رهان باسكال في الذكاء الاصطناعي (مترجم)

مقدمة
في عام 2008، كان الفيزيائيون الأوروبيون في سيرن CERN على وشك تفعيل مصادم الهدرونات العملاق لغاية رائعة. فقد باشر المصادم باختبار تنبؤات دقيقة لأكثر النظريات الفيزيائية الحالية أهميةً، متضمنة الرصد الصعب لبوزون هيغز. الأمر الذي تم في عام 2012 بنجاح في الحقيقة. على أيّ حال، طرح البعض من معارضي تفعيل المصادم اعتراضًا مضحكًا للغاية، مغلفًا بدعوى قدمها الكيميائي الألماني أوتو روسلر Otto Rossler ضد سيرن، حيث قال بأن تفعيل مصادم الهدرونات قد يخلق ثقبًا أسودًا مصغرًا قادر على تدمير الأرض وردًا على هذا، اعتبر معظم الفيزيائيين أن فرص حدوث كارثة كهذه ضئيلة جدًا، لكن لم يؤكد أي فيزيائي منهم أنها مستحيلة تمامًا. هنا، انبثقت معضلة عملية وفلسفية مهمة:
ما مدى احتمال فناء البشرية في نشاط ما، والذي يمكننا عنده أن نرجح كفة الفوائد الممكنة الحاصلة عند قيامنا بهذا النشاط عليه؟ بل كيف لنا حتى أن نبدأ بقياس خطر فناء البشرية جمعاء بالفوائد الأخرى؟
مؤخرًا، عبرت بعض الرموز البارزة كسام هاريس Sam Harris وإيلون ماسك Elon Musk عن اهتمامات مشابهة حول المخاطر الوجودية التي ستهدد البشرية جراء خلق الذكاء الاصطناعي. تلت تلك الاهتمامات أعمال لنيك بوستروم Nick Bostrom، مثلًا بحثه “قضايا أخلاقية في الذكاء الصنعي المتقدم” 2004. وإليزر يودكوفسكي Eliezer Yudkowsky، مثلًا “الذكاء الصنعي كعامل سلبي وإيجابي في الخطر العالمي” 2008. لنطلق على هذا الموقف اسم “مناهضة الإنجاب Anti-Natalism”. كونه يقترح أن المخاطر الإجمالية لخلق الذكاء الاصطناعي أكبر من فوائده المتوقعة، وبالتالي يجب ألّا يتم إنشاء الذكاء الاصطناعي.
على عكس مخاوف أوتو روسلر بشأن مصادم الهدرونات -والتي تم رفضها بشدة من قبل المجتمع العلمي- خصصت عدة مجموعات بحثية كمعهد مستقبل الحياة، ومعهد أبحاث الذكاء الآلي، ومركز كامبريدج لدراسة الأخطار الوجودية؛ ملايين الدولارات لما اعتبرته “يستحقّ التفكير فيه” فيما يخص استكشاف مخاطر الذكاء الاصطناعي. في الواقع، يتضمن المجال الجديد للمخاطر الوجودية الذكاء الاصطناعي كإحدى اهتماماته الرئيسة جنبًا إلى جنب مع التغير المناخي، والانتشار النووي، وتأثير الكويكبات واسع النطاق. لا يزال اللغز نفسه في مخاوف روسلر ساريًا هنا: إلى أي مدى يجب أن يكون احتمال فناء البشرية على يد الذكاء الاصطناعي كبيرًا حتى يتغلب على قيمة فوائده المحتملة؟
رهان باسكال الرهان الإلهي عند الرياضي
تأتي إحدى أجابات هذا السؤال من مصدر غير متوقع، هو حجة بليز باسكال في الإيمان بالإله. ففي كتابه “أفكار Pensees” (1670(، اقترح باسكال أنه يمكن لك أن تتوقع نتائج أفضل بكثير إذا ما قارنت حالة إيمانك بالله بحالة عدم إيمانك به. خصوصًا إذا كان هناك احتمال لأن يكافئ الله أولئك الذين آمنوا به بسعادة أبدية ويعاقب أولئك الذين لم يفعلوا بمعاناة أبدية. عندها سيكون من المنطقي أن تؤمن بالله حيث ستكون المكاسب (وكذلك الخسائر) لا متناهية إذا كان موجودًا، وستتجاوز هذه المكاسب دائمًا تلك المكاسب المحدودة التي يمكن أن تفوز بها في حالة عدم إيمانك به. إذًا فالإيمان بالله يعتبر رهانًا جيدًا. في الواقع، يعتبر الرهان العقلاني الوحيد، حتى لو كان من المرجح أن يوجد إله مختلف عن إلهك. وحتى لو خصصنا احتمالًا ضئيلًا للغاية لوجود الإله، فإن أي فرصة لتلقي مكاسب أو خسائر لا متناهية يجب أن تحفزك على الفور.
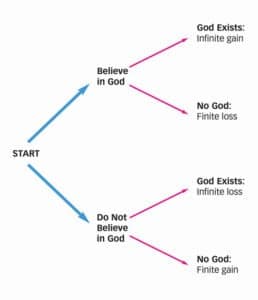
أسفر رهان باسكال عن مؤلفات أكاديمية كثيرة (تقدم المجموعة التي حررها بارثا Bartha وباسترناك Pasternack المسماة “رهان باسكال” 2018 نظرة شاملة مفيدة عن الموضوع). بل حتى أن الرهان قد كان أول تطبيق لنظرية القرار الحديثة. ومع ذلك، هناك مجموعة من الاعتراضات القوية على الرهان أدت إلى تجاهله بشدة في الفلسفة السائدة. فيما يلي تأتي أبرز الاعتراضات على رهان باسكال:
-مستحيل على الصعيد النفسي: إنه لمن المحال أن تجبر نفسك على الإيمان بمقترح ما حتى لو كان هذا الإيمان سيعطيك منافع أكثر.
-عدم جوازه أخلاقيًا: هناك شيء غير مقبول أخلاقيًا بشأن الإيمان بالله على أساس المنفعة المتوقعة، على النقيض من ذلك، وعلى سبيل المثال، يجب عليك الإيمان، لأنك تعتقد أن هناك أسباب وجيهة لهذا الإيمان.
إعلان
-استعمالاته للانهاية: هناك مشكلة في تخصيص فائدة لا متناهية لأي نتيجة، فما الذي تعنيه الفائدة اللامتناهية حتى؟
-العديد من الآلهة: هناك العديد من الآلهة المحتملين الذين قد يعاقبونك على إيمانك بالإله الخاطئ بتكاليف لا متناهية أيضًا. بمعنى آخر، كيف لك أن تعرف أي دين ستراهن عليه؟
أعتقد أن كل هذه الاعتراضات فعالة للغاية، على الرغم من وجود ردود مدروسة جيدًا طرحها مدافعون معاصرون، مثل ليكان Lycan وشليزينغر Schlesinger “راهن على حياتك You bet your life 1988″، وجوردان Jordan “رهان باسكال 2006″، وروتا Rota “نسخة أفضل من رهان باسكال 2016″، لكن مناقشة هذه الردود ليست ذات صلة بطرحنا الآن. بدلًا من ذلك، ستوفر لنا بنية رهان باسكال إطارًا مفيدًا لمناقشة “مناهضة الإنجاب” حول الذكاء الاصطناعي، الموقف الذي يعتبر الذكاء الاصطناعي خطيرًا جدًا على أن يتم خلقه.
رهان باسكال المعقولية والكارثة
إن فكرة باسكال الرئيسة والمرتبطة بمباحثاتنا عن الذكاء الاصطناعي هي أن وجود أي احتمال لحدوث خسائر لا متناهية سيكون أكثر أهمية من تحقيق أي مكاسب لا متناهية دومًا. لتعديل الفكرة قليلًا، يمكننا إضافة شرط على أي حدث لنأخذه بعين الاعتبار، والشرط هو أن تتجاوز احتمالية هذا الحدث عتبة معينة من المعقولية. لا يحقق خوف روسلر من تفعيل مصادم الهدرونات وخلق ثقب أسود صغير قادر على أن يبتلع الأرض. هذا الشرط، ولا يعتبر خطرًا وجوديًا معقولًا. بينما يفعل الذكاء الاصطناعي ذلك. ووفقًا لمنطق باسكال، فبمجرد أن يتحول الحدث إلى خطر معقول يترتب عليه خسائر لا متناهية، يجب أن نعطيه قيمة متوقعة سلبية لا نهائية، ثم نتصرف ضد حدوثه.
باستخدام هذا المعيار، ستبدو حجة مناهضة الإنجاب ضد الذكاء الاصطناعي كما يلي:
- إذا كان من المعقول لحدث ما أن يحمل خسائر لا متناهية؛ فسيكون خطره أكثر أهمية من أي مكاسب محدودة متوقعة.
- إن تدمير الذكاء الاصطناعي للبشرية سيعتبر خسارة لا متناهية.
- هناك احتمال معقول لفناء البشرية على يد الذكاء الاصطناعي.
النتيجة: المخاطر المحتملة للذكاء الاصطناعي تفوق أي فوائد محتملة.
أرى كل مقدمة من هذه المقدمات ذات مصداقية كبيرة، وكذلك الحجة نفسها.
أولًا: قدم مناهضو الإنجاب حجة جيدة جدًا لوجود احتمال عالي بشكل ملحوظ لكارثة الذكاء الاصطناعي. كما وصف بوستروم في كتاب الذكاء الفائق: طرق، ومخاطر، واستراتيجيات، هناك مجموعة واسعة ومتنوعة من القيم، لذلك فمن المرجح أن تتعارض قيم الذكاء الاصطناعي الخارق مع قيم البشر في النهاية، وأسهل طريقة لحل هذا الصراع هو إبادة البشرية. إذا دمر الذكاء الاصطناعي البشرية، فسيشكل ذلك فناءً لكل ما نعرفه ونهتم به الآن. سنقع في كارثة خسارتنا فيها لا متناهية. دعونا نطلق على هذا الحدث اسم AI Catastrophe a.
مع ذلك، حتى إذا قبلنا كل ما طرحه مناهضو الإنجاب وقبلنا شجرة القرار الباسكالية التي تم إعدادها لوصف رهانه، فقد لا يزال هناك بعض المكاسب اللا متناهية المحتملة التي يتم تجاهلها. لنضع هذا في الاتجاه المعاكس، قد تكون هناك بعض الخسائر اللامتناهية المرتبطة بعدم خلق الذكاء الاصطناعي!
يصور إسحاق عظيموف في قصته القصيرة العظيمة “السؤال الأخير The Last Question” (1956) مستقبلًا استعمرت فيه البشرية الكون المرصود. السؤال الوحيد الذي بقي حول صمود الحضارة البشرية عبر المجرات هو ما إذا كانت هذه الحضارة قادرة على التغلب على الموت الحراري الحتمي للكون، والناتج عن القانون الثاني في الديناميك الحراري. في القصة كان نجاح البشرية مدفوعًا إلى حد كبير بالذكاء الاصطناعي، وهذا يمثل مثالًا نادرًا للتفاؤل من بين الصور البائسة للعلاقة بين الحضارة البشرية والذكاء الاصطناعي في الخيال العلمي. لكن، تثير القصة سؤالًا مهمًا، وهو: هل يعتمد استمرار وانتشار الحضارة البشرية في المستقبل على تطوير ذكاء اصطناعي فائق؟
إنه لمن المهم أن ندرك أن هذا السؤال جائز وتجريبي؛ ذلك أنه يوجد احتمالية غير معروفة بدقة حتى الآن للتنبؤ بأن الإنسانية لا يمكن لها أن تنجو من التهديدات الوجودية المختلفة دون خلق ذكاء اصطناعي فائق. وإذا تبين أن هذا التنبؤ صحيح، ولم نكن قد طورنا الذكاء الاصطناعي بعد؛ سيعني هذا دمار الحياة الإنسانية وفناء كل شيء عملت هذه الحياة من أجله، وستكون النتيجة نفس نتيجة الحدث AI Catastrophe a. لذا، بروح الوسم، دعونا نطلق على فكرة انقراض البشرية نتيجة عدم خلق ذكاء اصطناعي اسم AI Catastrophe B. مهما كانت الاحتمالية التي سنخصصها لهذا الحدث، طالما أنها أكبر من الصفر بما يكفي لتكون معقولة، فإن هذه الكارثة المحتملة يجب أن تكون أيضًا جزءًا أساسيًا من حساب قيمة “الحكمة” من خلق الذكاء الاصطناعي.
شخصيًا، أجد أن هذه الكارثة تتجاوز عتبة المعقولية بشدة. بإدخال AI Catastrophe B في شجرة قرار خلق الذكاء الاصطناعي، ستتغير حساباتنا تمامًا.
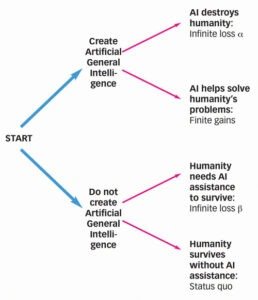
في شجرة القرار الجديدة هذه، ينتج عن التفكير بأسلوب باسكال أنه إذا كان كل من AI Catastrophe a وAI Catastrophe B فوق عتبة المعقولية. فإن نتائجهما السلبية اللامتناهية ستلغي أثر بعضها البعض! أي أن الخطر الوجودي الذي يشكله خلق الذكاء الاصطناعي يكافئ الخطر الوجودي الذي يشكله عدم خلقه! الاعتبارات الوحيدة المتبقية لنا هي الفوائد المحتملة للذكاء الاصطناعي مقارنة بفوائد الوضع الراهن دون امتلاك ذكاء اصطناعي. في هذه المقارنة، من الواضح أن وجود الذكاء الاصطناعي أفضل، ومن السهل استنتاج ذلك عندما نفكر في “المكاسب المحدودة” المحتملة المدرجة في هذه الفئة، المكاسب التي تشمل أشياء من قبيل القضاء على الفقر والمرض والملل والحرب. بناءً على ذلك، يقودنا التفكير بأسلوب باسكال إلى استنتاجٍ مفاده أن إنشاء الذكاء الاصطناعي هو الخيار الأفضل دائمًا للبشرية.
الرهان النووي
قد تكون هذه الحجة أكثر بدهية عند تطبيقها على مخاطر وجودية مألوفة أكثر. على سبيل المثال، يفترض الناس الذين عارضوا تطوير الأسلحة النووية عادةً أن المردود من عدم تطويرها هو ببساطة مكسب أو خسارة مباشرة للوضع الراهن على أي حال، هناك حجة مرتبطة بالعالم السياسي كينيث والتز 1981 مفادها أن “انتشار مزيد من الأسلحة النووية، قد يكون أفضل”، حيث تقول أن الأسلحة النووية حققت تأثيرًا رادعًا، أسفر عن فترة السلام الطويلة التي عرفناها منذ عام 1945. تقترح النسخة المتطرفة من حجة والتز أن الأسلحة النووية هي الشيء الوحيد الذي يمكن أن يملك تأثير سلمي على العالم. إن ادعاء والتز جدلي للغاية، والنسخة المتطرفة أكثر جدلية منه بكثير، ولن أدافع عن أي من النسختين. مع ذلك، يجب على المعارضين لانتشار الأسلحة النووية أن يستمتعوا بحجة والتز. إذا ربطت بعض الاحتمالات المعقولة بكل من الهولوكوست النووي الذي سببته الأسلحة النووية والهولوكوست غير النووي في غياب هذه الأسلحة. فيمكن أن ينطبق هنا نفس نمط التفكير الذي رأيناه في قضية الذكاء الاصطناعي.
هل تفوق مكاسب امتلاك الأسلحة النووية مكاسب عدم امتلاكها أهميةً؟ هذا لا يمكن تخمينه بسهولة، لكن المكاسب المحدودة للذكاء الاصطناعي يمكن أن تحسب بسهولة أكبر. بعد تأكُّدنا من معقولية الكوارث التي ستحصل في حالة وجود الذكاء الاصطناعي، وفي حالة عدم وجوده، تبين أننا سنحتاج أن نناقش الفوائد الممكنة فقط.
كاتب المقال: Dr. Derek Leben المصدر
إعلان